Kureringsarbete med riksdagsdata och BLM
Under våren 2023 har arbetet med att fortsätta städa och kurera riksdagsprotokoll fortsatt. Arbetet är omfattande och glädjande nog har Westac-projektet härvidlag fått draghjälp av ett RJ-finansierat infraprojekt, SWERIK: Swedish Riksdag 1867–2022: An Ecosystem of Linked Open Data. Det projektet leds av Fredrik Norén vid Malmö universitet (som även ingår i Westac-projektet). På KB-labb fortgår därtill arbetet med att iordningställa de romaner som digitaliserats inom projektet, liksom tidskriften Bonniers Litterära Magasin. Inom projektet är det främst Alexandra Borg på Uppsala universitet som intresserar sig för BLM, och till vår hjälp har vi anställt statistikstudent Liam Tabibzadeh (också vid Uppsala) för att iordningställa BLM för analys. Liam kommer förhoppningsvis att under hösten skriva en bloggpost om sitt arbete.
Projektuppdatering inför hösten 2022
Välfärdsstaten analyserad har som forskningsprojekt nu pågått ett par år. Ett flertal texter har publicerats och samarbetet mellan KB-labb, Humlab och forskare vid Lund, Umeå och Uppsala universitet rullar ungefär som tänkt. Robin Saberi – som varit anställd som forskningsassistent i projketet (vid Statistiska institutionen på Uppsala universitet) – kommer dock att lämna projektet för annat arbete. Vi tackar, bugar och bockar för de arbete som Robin lagt ned. Forskningsmässigt är det framför allt riksdagsmaterial som projeketet ägnat sig åt – delvis som en effekt att detta material är enklast att hantera. Så kommer exempelvis Snickars att i dagarna göra en presentation av dessa materialkategorier på XXIII International Congress of Historical Sciences i Poznan, Polen. Under hösten är det emellertid vår ambition att sätta samman alla de skönlitterära romaner och alla årgångar av Bonniers litterära magasin som digitaliserats till större dataset som vi sedermera kan beforska. Tanken är att här på projektbloggen informera – något mer än tidigare – kring hur detta arbete fortlöper.
Projektuppdatering – ungefär i halvtid
Forskningsprojektet Välfärdsstaten analyserad har i skrivande stund kommit ungefär halvvägs. På grund av pandemin kommer projekttiden med all sannolikhet att förlängas – projektet kommer att pågå en bit in på 2024. Arbetet fortskrider ungefär som planerat, med vissa modifikationer. Generellt kan man säga att projektarbetet har innefattat tre olika moment: digitalisering, kurering och forskning. Med Kungliga bibliotekets hjälp har digitaliseringen av Bonniers litterära magasin slutförts, men vi har emellertid bestämt att även resterande årgångar av tidskriften ska digitaliseras och inte bara dem som täcker projekttiden (1945-89). De arbetet kommer att slutföras under våren 2022. På samma sätt fortskrider digitaliseringen av svensk skönlitteratur; uppemot två tusen titlar har nu digitaliserats. Det arbetet har varit mer resurskrävande än vad vi antog från början, så med all sannolikhet kommer de medel som avsatts inte att räcka för hela projektperioden. Men både BLM och romanerna kommer att under 2022 sammanställas som dataset för forskning. För detta ändamål kommer det att krävas en hel del kureringsarbete – som projektet genomför i samarbete med KB-labb. Där har vi arbetat en del med dagspress, men framför allt koncentrerat oss på att kurera ett mycket omfattande dataset av riksdagsdebatter. Om analysperioden för BLM gjorts mer omfattande, så gäller det även för riksdagsdatan där vi arbetet med ett hundraårsperspektiv (från idag till början 1920-talet). Projektets statistiker och maskininlärningsexperter har lagt ned mycket möda på att städa data (på automatisk väg) liksom att förse datasetet med metadata kring talare, partitillhörighet, kön och geografi. Vi räknar med att detta dataset kommer att bli tillgängligt för forskning nu strax före årskiftet 2021/22. I övrigt har en hel del forskningsarbete lagts ned på det SOU-material som vi bland annat skapat en rad olika temamodeller kring. På den kommande digitala historiekonferensen vid Humlab kommer olika aspekter av arbetet inom Välfärdsstaten analyserad att presenteras.
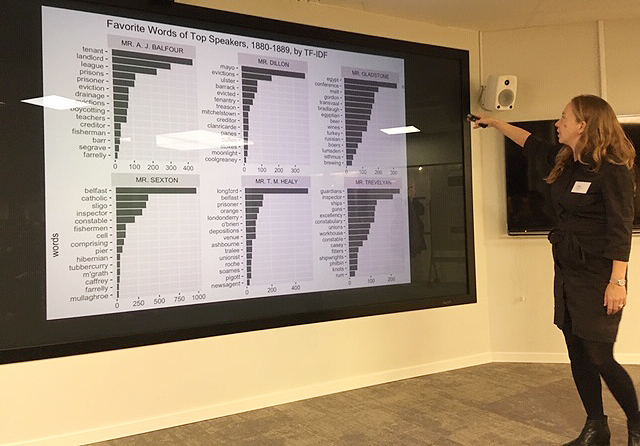
Uppmärkning av Riksdagsdebatter 1920–2019
Sedan hösten 2020 har mycket tid i Westac-projektet ägnats åt att kurera och märka upp en större korpus med riksdagsdebatter. Mer specifikt handlar det om de senaste hundra åren av politiska anföranden (Kammarens protokoll) från 2020 till 2019 – en period som bland annat präglades av demokratins genombrott, konsolidering och transformering.
Materialet har digitaliserats i två omgångar. Enkammarriksdagens protokoll (1971–) har funnits tillgängliga i digitalt format sedan början av 2000-talet. Sedan några år tillbaka har även Ståndriksdagen (1521–1866) och Tvåkammarriksdagen (1867–1970) i digitaliserat. Det är ett rikt och spännande material för alla som är intresserade av politik och dess kulturella former – och allt finns naturligtvis fritt tillgängligt (https://riksdagstryck.kb.se/ och https://data.riksdagen.se/)!
Frågeställningarna som vi nu kan ställas till detta material i sin helhet är enkla men potenta: Vilka frågor var distinkt kvinnliga respektive manliga med avseende på vem som debatterade dem? Hur har stad–landsbygd diskuterats av riksdagsledamöter som representerade storstäder respektive mindre orter? Hur har olika partier diskuterat frågor om frihet och jämlikhet? Och hur har allt detta förändrats över tid?
Men för att dessa frågor effektivt ska kunna utforskas med hjälp av datorstödda metoder behöver riksdagsdebatterna märkas upp med relevant metadata. OCR-kvalitén är överlag god, men det saknas information i den bakomliggande XML-strukturen som anger information om talarna (namn, kön, partitillhörighet och geografisk representation) och om om riksdagsanföranden (exempelvis när de börjar och slutar). Det senare är relevant eftersom dokumentserien Kammarens protokoll både innehåller politiska anföranden och redogörelser för aktiviteter som händer i kammaren.
Detta är ett arbete som Westac sysslar med nu, genom ett samarbete mellan projektets humanistiska forskare, statistiker och systemutvecklare. Här gifts humanistens kritiska materialkännedom samman med statistikerns förmåga att reducera text till programmeringsbara beståndsdelar. Förhoppningsvis har vi snart en uppmärkt korpus som vi kan använda för att utforska svensk politik på hela nya sätt – och som naturligtvis också kommer att tillgängliggöras för andra forskare.
Temamodellering av SOU:er i öppen Jupyter notebook
Inom ramen för vårt forskningsprojekt har vi gjort en så kallad Jupyter notebook publikt tillgänglig. I den kan temamodellering av ett dataset om 3154 statliga offentliga utredningar – publicerade mellan 1945 och 1989 – utföras. Det rör sig om cirka 87 miljoner ord. Genom temamodellering (topic modeling på engelska) kan algoritmer klassificera stora korpusar baserat på tematiska strukturer i textmassan. Grundfrågan handlar om vilka diskurser, motiv eller tematiker som kan ha tänkts skapat de dokument som forskaren intresserar sig för. I Jupyter är det en modell som delar in SOU-materialet i 200 teman som gjorts tillgänglig. Dessa teman har inga beteckningar utan listas enbart i stigande nummerordning (från 0 till 199). Mer information om temamodellering av offentliga utredningar finns här.
- Klicka på denna länk – och klicka därefter på den svartblå “launch binder”-knappen. Det tar lite tid för sidan att ladda.
- Jupyter notebooks körs via olika kodceller: markera den första grå rutan (” In [1]: import os”) – och tryck sedan på knappen Run i menyn ovan.
- Vänta in en rad nedladdningar – och att symbolen “BokehJS 2.2.3 successfully loaded” syns.
- Markera den andra grå rutan (“In [2]: import os”) under rubriken “PREPARE Load Topic Model” – och tryck sedan på knappen Run i menyn ovan.
- För att köra resterande kodceller – gör på samma sätt som ovan.
1890-talets skönlitteratur som data
Inom Westac ägnar vi oss för närvarande åt att digitalisera svensk skönlitteratur från 1950-talet. Arbetet har påbörjats av KB – men det kommer att ta tid innan ett mer omfattande korpus är färdigt. För att påbörja forskningsarbetet med att analysera skönlitteratur som data har vi därför iordningställt ett jämförande dataset av svensk skönlitteratur från 1890-talet. Årtiondet är godtyckligt valt. Tanken är främst att framgent testa modeller och algoritmer. Storskalig textanalys av skönlitteratur från ett helt årtionde kan potentiellt ge insikter om större mönster, teman och diskurser som analys av enskilda böcker inte kan uppenbara. Sådan textanalys baserar sig emellertid på ett dataset som forskaren själv konstruerar – vilket enbart maskiner förmår att “läsa”. Så kallad distansläsning ersätter inte närläsning, men den kan utgöra ett värdefullt komplement. Som flera litteraturvetare framhållit så innebär storskalig textanalys också att ett snävt urval av skönlitteratur (kanon) ersätts av i princip allt som publicerades under en viss tidsperiod (förutsatt att alla böcker digitaliserats).
Den här bloggposten handlar dock inte om analys av det dataset av svensk skönlitteratur från 1890-talet som vi satt samman; det måste bland annat först köras igenom Språkbankens annoteringsverktyg Sparv för att skapa ett textkorpus av exempelvis lemmatiserade substantiv (det finns en specifik modell för 1800-tals-svenska). Poängen med detta inlägg är istället att redovisa hur vårt dataset konstruerats. Det är nämligen inte helt enkelt att bygga dataset av skönlitteratur; det är alltid en aktivitet som bygger på ett antal val och mer eller mindre subjektiva kriterier. Inom digital humaniora framhålls ofta att iordnigställandet av dataset är en tidskrävande aktivitet; att förbereda detta dataset är inte något undantag. Vårt dataset innehåller knappt 300 titlar publicerade mellan 1890 till 1899. Det handlar om romaner skrivna av svenska författare, liksom novellsamlingar och i enstaka fall varianter av prosalyrik. I vårt dataset ingår kanonsierade klassiker av Strindberg, Lagerlöf och Heidenstam, men främst innehåller det böcker som helt fallit i glömska – även om de publicerats av renommerade förlag som Bonniers, Norstedts eller Wahlström & Widstrand. Några få böcker är publicerade anonymt, i de fall där författare använt pseudonym har det egentliga författarnamnet använts. Barnböcker är inte medtagna, och inte heller nyupplagor av äldre böcker. Finlandssvenska författare som skriver på svenska har också sorterats ut, liksom korta skönlitterära titlar på ett fåtal sidor.
Utgångspunkten för urvalet av böcker till vårt dataset har varit sökningar i Libris på “år:(1890) språk:swe”, samt flikarna “Skönlitteratur” och “e-resurs”. Det säger sig självt att vårt urval är baserat på de böcker som digitaliserats – inte sällan på beställning av andra forskare. Man kan exempelvis notera att bland 1890-talets digitaliserade romaner så är det osedvanligt många som har ett äldre historiskt tema. Med utgångspunkt i kriterierna ovan resulterade det likväl i ett dataset om 291 titlar. Enligt Johan Svedjedals studie Bokens samhälle (1993) så publicerades drygt 800 titlar inom kategorin “fiktionsprosa för vuxna” i Sverige under 1890-talet. Vårt dataset innehåller med andra ord mindre än hälften av det som faktiskt publicerades.
Somliga böcker som ingår i vårt dataset kommer från Projekt Runeberg, andra från KB. Men merparten härstammar från det samarbete mellan Litteraturbanken och universitetsbiblioteken i Göteborg, Lund, Umeå och Uppsala som pågått under ett antal år där alla tryckta texter OCR-tolkats till maskinläsbar text. Storskalig textanalys kan inte utföras på PDF:er av böcker utan förutsätter att skönlitteratur omvandlas till txt-filer (eller motsvarande). På Litteraturbanken finns en del böcker tillgängliga i epub-format; de är att föredra eftersom de konvertrar bättre till txt-filer än PDF. Texten flödar då i regel utan radbrytningar och sidnummer försvinner. Laddar man ned epub-filer så finns det många öppna konverteringsprogram på webben som är snabba och enkla att använda, som exempelvis zamsar.com. Via Litteraturbanken och Projekt Runeberg kan vissa titlar laddas ned som txt-filer – men i huvudsak har vi använt oss av Wget, en öppen mjukvara som normalt körs via en kommandotolk (ett textbaserat användargränssnitt under Linux). Wget är ett program för filöverföring; det processar inga filer – men kombinerat med kommandot “pdftotext” (ett annat terminalprogram) kan man enkelt ladda ned böcker både som PDF och som OCR-tolkade txt-filer. Wget automatiserar alltså arbetet att öppna PDF, markera och kopiera text och spara till fil. Kvaliteten på de inskannade böckerna i PDF-format är i regel mycket god, likväl varierar OCR-tolkningen efter hur böcker är satta, vilket typsnitt som använts och boksidans allmänna utseende. Noterbart är att de fåtal romaner som under 1890-talet (delvis) sattes i frakturstil genererar en teckentolkning som knappt är läsbar alls.
Med hjälp av Wget har 291 txt-filer laddats hem – och därefter städats. I regel har texter tvättas i början – där information om vem som digitaliserat boken ofta är nämnt, därtill mot slutet av texten där det inte sällan förekommer recensioner eller reklam för författarens tidigare böcker eller andra publikationer från förlaget. OCR-motorn har därtill ofta problem med titlar och metadata om boken (tryckår, förlag etcetera) vilket inte sällan resulterar i ett omfattande textbrus som måste avlägsnas. Det säger sig självt att OCR-motorn har det speciellt besvärligt med textornament som anfanger – som enbart återges som textbrus. Illustrerade romaner blir förstås också osedvanligt smutsiga. Innehållsförteckningar har tagits bort liksom i vissa fall boktitlar som återkommande figurerar i sidhuvudet. Generellt har txt-filerna ett rudimentärt utseende: i början listas författarnamn, titel och årtal (ibland förlag) – samma metadata har använts för att benämna böckerna (StrindbergA_Inferno_1897.txt).

Om det “politiska” i kommande konferenspublikation
I slutet av våren deltog Westac-projektet i en första konferns på temat “Digitised newspapers – a new Eldorado for historians?”, ett anförande som nu antagits i en kommande OA-publikation från förlaget De Gruyter. I ett kortare abstract framgår vad artikeln kommer att handla om: “The aim of the article is to present, examine and explore the development of the concept of ‘the political’ in Swedish newspaper data – gleaned from four major newspapers – during the post-war era. The traditional assumption is that ‘the political’ increased and diversified dramatically during the 1960s and 1970s with new notions as ‘the personal is political’, ‘political consciousness’ and even ‘political fantasy’. The article empirically examines this assumption by first extracting and studying bigrams for notions of ‘the political’ from the newspaper data, and then deepen the analysis with explorative tools for topic modeling and network analysis.” När artikeln väl är publicerad kommer vi att ladda upp en version på projekthemsidan.
Notes from the conference Computational Text Analysis and Historical Change
Last week, Erik and Fredrik from WeStAc arranged the symposium “Computational Text Analysis and Historical Change” in Humlab, the digital humanities center at Umeå University. This interdisciplinary event gathered 15 speakers, including five keynotes, from 8 different countries. Some of the talks included concrete and hands-on examples of how to detect prejudices about race in American 19th century fiction, and how different weight measurements can reveal unknown topics in political debates. More importantly, the symposium generated valuable discussions on a more general level: How do we apply a “purposeful data modification” (to quote David Mimno’s keynote) in our research process? And, as Patricia Murrieta Flores rhetorically asked, how do we use computational methods of today to study space and place in texts from a historical time when space and place were understood in a completely different way? For us working with the WeStAc project we got a lot of inspiration and creative ideas, as well as hands on advices of what one should do (and not do) when engaging with large-scale text analysis methods.

Computational Text Analysis and Historical Change – September Conference at Humlab
As one of the first research activities linked to the project Welfare State Analytics, project members Erik Edoff and Fredrik Norén are arranging an international conference at Humlab, Umeå University: “Computational Text Analysis and Historical Change” on September 4–6. The starting point of this interdisciplinary event is as follows: Considering the possibility to process large amounts of text data through methods such as probabilistic topic models or word embeddings, how can historical transformations of culture and society be empirically measured in novel ways? The conference will have five keynote speakers: Sarah Allison (Loyloa University),Jo Guldi (Southern Methodist University), David Mimno (Cornell University), Patricia Murrieta-Flores (Lancaster University) and Mikko Tolonen (University of Helsinki). If you are interested in attending – contact erik.edoff@umu.se or fredrik.noren@umu.se. The full program can be found here:

Första blogginlägget
Fredagen den 10:e maj påbörjades forskningsprojektet “Välfärdsstaten analyserad. Textanalys och modellering av svensk politik, media och kultur, 1945-1989” på Kungliga biblioteket. Det är ett långt projekt (fem år), men vi är alla nöjda med att äntligen få dra igång projektet. I den första fasen handlar det visserligen mest om att påbörja ett samarbete mellan oss universitetsforskare och utvecklare och personal på Humlab och det nya KBlabb – liksom att få den tekniska infrastruktren på plats. Eftersom projektet kommer att arbeta med flera stora dataset lutar det åt att vi under hösten framför allt kommer att koncentrera oss på att iordningsställa den data som finns (i de redan digitaliserade) Statliga offentliga utredningarna samt den data som ligger öppen på Riksdagens öppna data. På den här bloggen kommer vi att kontinuerligt uppdatera vad som händer i projektet – liksom de aktiviteter vi ägnar oss åt.